kmeans#
- scipy.cluster.vq.kmeans(obs, k_or_guess, iter=20, thresh=1e-05, check_finite=True, *, rng=None)[Quelle]#
Führt k-means für eine Menge von Beobachtungsvektoren durch, die k Cluster bilden.
Der k-means-Algorithmus passt die Klassifizierung der Beobachtungen in Cluster an und aktualisiert die Cluster-Zentren, bis die Position der Zentren über aufeinanderfolgende Iterationen stabil ist. In dieser Implementierung des Algorithmus wird die Stabilität der Zentren durch den Vergleich des Absolutwerts der Änderung der durchschnittlichen Euklidischen Distanz zwischen den Beobachtungen und ihren entsprechenden Zentren mit einem Schwellenwert bestimmt. Dies ergibt eine Code-Tabelle, die Zentren auf Codes und umgekehrt abbildet.
- Parameter:
- obsndarray
Jede Zeile des M mal N großen Arrays ist ein Beobachtungsvektor. Die Spalten sind die Merkmale, die bei jeder Beobachtung erfasst wurden. Die Merkmale müssen zuerst mit der Funktion
whitenweißgefiltert werden.- k_or_guessint oder ndarray
Die Anzahl der zu generierenden Zentren. Jedem Zentrum wird ein Code zugewiesen, der auch der Zeilenindex des Zentrums in der generierten Code-Tabellen-Matrix ist.
Die anfänglichen k Zentren werden durch zufälliges Auswählen von Beobachtungen aus der Beobachtungsmatrix ausgewählt. Alternativ kann die Angabe eines k mal N großen Arrays die anfänglichen k Zentren spezifizieren.
- iterint, optional
Die Anzahl der Durchläufe von k-means, wobei die Code-Tabelle mit der geringsten Verzerrung zurückgegeben wird. Dieses Argument wird ignoriert, wenn anfängliche Zentren mit einem Array für den Parameter
k_or_guessangegeben werden. Dieser Parameter stellt nicht die Anzahl der Iterationen des k-means-Algorithmus dar.- threshfloat, optional
Beendet den k-means-Algorithmus, wenn die Änderung der Verzerrung seit der letzten k-means-Iteration kleiner oder gleich dem Schwellenwert ist.
- check_finitebool, optional
Ob überprüft werden soll, ob die Eingabematrizen nur endliche Zahlen enthalten. Deaktivieren kann die Leistung verbessern, kann aber zu Problemen (Abstürze, Nicht-Terminierung) führen, wenn die Eingaben Unendlichkeiten oder NaNs enthalten. Standard: True
- rng{None, int,
numpy.random.Generator}, optional Wenn rng als Schlüsselwort übergeben wird, werden andere Typen als
numpy.random.Generatorannumpy.random.default_rngübergeben, um einenGeneratorzu instanziieren. Wenn rng bereits eineGenerator-Instanz ist, dann wird die bereitgestellte Instanz verwendet. Geben Sie rng für reproduzierbares Funktionsverhalten an.Wenn dieses Argument positionsabhängig übergeben wird oder seed als Schlüsselwort übergeben wird, gilt das Legacy-Verhalten für das Argument seed.
Wenn seed None ist (oder
numpy.random), wird die Singleton-Instanz vonnumpy.random.RandomStateverwendet.Wenn seed eine Ganzzahl ist, wird eine neue
RandomState-Instanz mit seed verwendet.Wenn seed bereits eine
Generator- oderRandomState-Instanz ist, dann wird diese Instanz verwendet.
Geändert in Version 1.15.0: Als Teil des SPEC-007-Übergangs von der Verwendung von
numpy.random.RandomStatezunumpy.random.Generatorwurde dieses Schlüsselwort von seed zu rng geändert. Für eine Übergangszeit werden beide Schlüsselwörter weiterhin funktionieren, obwohl nur eines gleichzeitig angegeben werden kann. Nach der Übergangszeit werden Funktionsaufrufe mit dem Schlüsselwort seed Warnungen ausgeben. Das Verhalten von sowohl seed als auch rng ist oben beschrieben, aber nur das Schlüsselwort rng sollte in neuem Code verwendet werden.
- Rückgabe:
- codebookndarray
Ein k mal N großes Array von k Zentren. Das i-te Zentrum codebook[i] wird mit dem Code i dargestellt. Die generierten Zentren und Codes stellen die geringste beobachtete Verzerrung dar, nicht unbedingt die global minimale Verzerrung. Beachten Sie, dass die Anzahl der Zentren nicht notwendigerweise gleich dem Parameter
k_or_guessist, da Zentren, denen keine Beobachtungen zugeordnet sind, während der Iterationen entfernt werden.- distortionfloat
Die mittlere (nicht quadrierte) Euklidische Distanz zwischen den übergebenen Beobachtungen und den generierten Zentren. Beachten Sie den Unterschied zur Standarddefinition von Verzerrung im Kontext des k-means-Algorithmus, die die Summe der quadrierten Distanzen ist.
Siehe auch
Hinweise
Für mehr Funktionalität oder optimale Leistung können Sie sklearn.cluster.KMeans verwenden. Dies ist ein Benchmark-Ergebnis mehrerer Implementierungen.
kmeanshat experimentelle Unterstützung für Python Array API Standard-kompatible Backends zusätzlich zu NumPy. Bitte erwägen Sie das Testen dieser Funktionen, indem Sie eine UmgebungsvariableSCIPY_ARRAY_API=1setzen und CuPy, PyTorch, JAX oder Dask Arrays als Array-Argumente bereitstellen. Die folgenden Kombinationen von Backend und Gerät (oder anderen Fähigkeiten) werden unterstützt.Bibliothek
CPU
GPU
NumPy
✅
n/a
CuPy
n/a
⛔
PyTorch
✅
⛔
JAX
⚠️ kein JIT
⛔
Dask
⚠️ berechnet Graph
n/a
Siehe Unterstützung für den Array API Standard für weitere Informationen.
Beispiele
>>> import numpy as np >>> from scipy.cluster.vq import vq, kmeans, whiten >>> import matplotlib.pyplot as plt >>> features = np.array([[ 1.9,2.3], ... [ 1.5,2.5], ... [ 0.8,0.6], ... [ 0.4,1.8], ... [ 0.1,0.1], ... [ 0.2,1.8], ... [ 2.0,0.5], ... [ 0.3,1.5], ... [ 1.0,1.0]]) >>> whitened = whiten(features) >>> book = np.array((whitened[0],whitened[2])) >>> kmeans(whitened,book) (array([[ 2.3110306 , 2.86287398], # random [ 0.93218041, 1.24398691]]), 0.85684700941625547)
>>> codes = 3 >>> kmeans(whitened,codes) (array([[ 2.3110306 , 2.86287398], # random [ 1.32544402, 0.65607529], [ 0.40782893, 2.02786907]]), 0.5196582527686241)
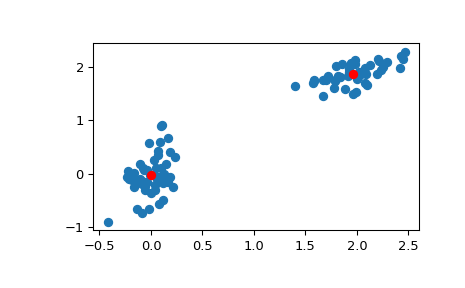
>>> # Create 50 datapoints in two clusters a and b >>> pts = 50 >>> rng = np.random.default_rng() >>> a = rng.multivariate_normal([0, 0], [[4, 1], [1, 4]], size=pts) >>> b = rng.multivariate_normal([30, 10], ... [[10, 2], [2, 1]], ... size=pts) >>> features = np.concatenate((a, b)) >>> # Whiten data >>> whitened = whiten(features) >>> # Find 2 clusters in the data >>> codebook, distortion = kmeans(whitened, 2) >>> # Plot whitened data and cluster centers in red >>> plt.scatter(whitened[:, 0], whitened[:, 1]) >>> plt.scatter(codebook[:, 0], codebook[:, 1], c='r') >>> plt.show()