order_statistic#
- scipy.stats.order_statistic(X, /, *, r, n)[Quelle]#
Wahrscheinlichkeitsverteilung einer Ordnungsstatistik
Gibt eine Zufallsvariable zurück, die der zugrundeliegenden Verteilung der \(r^{\text{ten}}\) Ordnungsstatistik einer Stichprobe von \(n\) Beobachtungen einer Zufallsvariable \(X\) folgt.
- Parameter:
- XContinuousDistribution
Die Zufallsvariable \(X\)
- rarray_like
Der (positive ganze) Rang der Ordnungsstatistik \(r\)
- narray_like
Die (positive ganze) Stichprobengröße \(n\)
- Rückgabe:
- YContinuousDistribution
Eine Zufallsvariable, die der Verteilung der vorgeschriebenen Ordnungsstatistik folgt.
Hinweise
Wenn wir \(n\) Beobachtungen einer kontinuierlichen Zufallsvariable \(X\) machen und diese in aufsteigender Reihenfolge sortieren \(X_{(1)}, \dots, X_{(r)}, \dots, X_{(n)}\), dann ist \(X_{(r)}\) als die \(r^{\text{te}}\) Ordnungsstatistik bekannt.
Wenn die Dichtefunktion (PDF), die kumulative Verteilungsfunktion (CDF) und die komplementäre kumulative Verteilungsfunktion (CCDF) der zugrundeliegenden math:X als \(f\), \(F\) und \(F'\) bezeichnet werden, dann ist die Dichtefunktion der zugrundeliegenden math:X_{(r)} gegeben durch
\[f_r(x) = \frac{n!}{(r-1)! (n-r)!} f(x) F(x)^{r-1} F'(x)^{n - r}\]Die CDF und andere Methoden der Verteilung von \(X_{(r)}\) werden unter Verwendung der Tatsache berechnet, dass \(X = F^{-1}(U)\), wobei \(U\) eine standardmäßige gleichverteilte Zufallsvariable ist, und dass die Ordnungsstatistiken von Beobachtungen von U einer Beta-Verteilung folgen, \(B(r, n - r + 1)\).
Referenzen
[1]Ordnungsstatistik. Wikipedia. https://en.wikipedia.org/wiki/Order_statistic
Beispiele
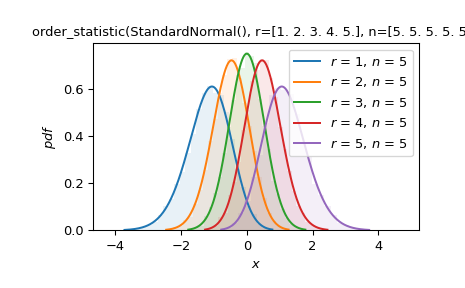
Nehmen wir an, wir sind an Ordnungsstatistiken von Stichproben der Größe fünf interessiert, die aus der Standardnormalverteilung gezogen wurden. Stellen Sie die Dichtefunktion jeder Ordnungsstatistik dar und vergleichen Sie sie mit einem normalisierten Histogramm aus einer Simulation.
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy import stats >>> >>> X = stats.Normal() >>> data = X.sample(shape=(10000, 5)) >>> sorted = np.sort(data, axis=1) >>> Y = stats.order_statistic(X, r=[1, 2, 3, 4, 5], n=5) >>> >>> ax = plt.gca() >>> colors = plt.rcParams['axes.prop_cycle'].by_key()['color'] >>> for i in range(5): ... y = sorted[:, i] ... ax.hist(y, density=True, bins=30, alpha=0.1, color=colors[i]) >>> Y.plot(ax=ax) >>> plt.show()