NumericalInverseHermite#
- class scipy.stats.sampling.NumericalInverseHermite(dist, *, domain=None, order=3, u_resolution=1e-12, construction_points=None, random_state=None)#
Hermite-Interpolation-basierte INVERSION der CDF (HINV).
HINV ist eine Variante der numerischen Inversion, bei der die inverse CDF mittels Hermite-Interpolation approximiert wird, d.h. das Intervall [0,1] wird in mehrere Intervalle aufgeteilt und in jedem Intervall wird die inverse CDF durch Polynome approximiert, die mithilfe von Werten der CDF und PDF an den Intervallgrenzen konstruiert werden. Dies ermöglicht es, die Genauigkeit durch Aufteilung eines bestimmten Intervalls zu verbessern, ohne Berechnungen in unberührten Intervallen wiederholen zu müssen. Drei Arten von Splines sind implementiert: lineare, kubische und quintische Interpolation. Für die lineare Interpolation wird nur die CDF benötigt. Die kubische Interpolation erfordert auch die PDF und die quintische Interpolation die PDF und ihre Ableitung.
Diese Splines müssen in einem Einrichtungsschritt berechnet werden. Dies funktioniert jedoch nur für Verteilungen mit begrenztem Definitionsbereich; für Verteilungen mit unbegrenztem Definitionsbereich werden die Enden abgeschnitten, so dass die Wahrscheinlichkeit für die Endregionen im Vergleich zur gegebenen u-Auflösung gering ist.
Die Methode ist nicht exakt, da sie nur Zufallsvariablen der approximierten Verteilung erzeugt. Dennoch kann der maximale numerische Fehler in „u-Richtung“ (d.h.
|U - CDF(X)|, wobeiXdas approximierte Perzentil ist, das dem QuantilUentspricht, d.h.X = approx_ppf(U)) auf die erforderliche Auflösung (innerhalb der Maschinenpräzision) eingestellt werden. Beachten Sie, dass sehr kleine Werte der u-Auflösung möglich sind, aber die Kosten für den Einrichtungsschritt erhöhen können.- Parameter:
- distObjekt
Eine Instanz einer Klasse mit einer
cdfund optional einerpdfunddpdfMethode.cdf: CDF der Verteilung. Die Signatur der CDF wird erwartet als:def cdf(self, x: float) -> float. D.h. die CDF sollte einen Python-Float akzeptieren und einen Python-Float zurückgeben.pdf: PDF der Verteilung. Diese Methode ist optional, wennorder=1ist. Muss die gleiche Signatur wie die PDF haben.dpdf: Ableitung der PDF nach der Zufallsvariablen (d.h.x). Diese Methode ist optional mitorder=1oderorder=3. Muss die gleiche Signatur wie die CDF haben.
- domainListe oder Tupel der Länge 2, optional
Die Unterstützung der Verteilung. Standard ist
None. WennNoneWenn eine
support-Methode vom Verteilungsobjekt dist bereitgestellt wird, wird sie verwendet, um den Definitionsbereich der Verteilung festzulegen.Andernfalls wird die Unterstützung als \((-\infty, \infty)\) angenommen.
- orderint, Standardwert:
3 Setzt die Ordnung der Hermite-Interpolation. Gültige Ordnungen sind 1, 3 und 5. Beachten Sie, dass Ordnungen größer als 1 die Dichte der Verteilung erfordern, und Ordnungen größer als 3 sogar die Ableitung der Dichte erfordern. Die Verwendung der Ordnung 1 führt bei den meisten Verteilungen zu einer riesigen Anzahl von Intervallen und wird daher nicht empfohlen. Wenn der maximale Fehler in u-Richtung sehr klein ist (z.B. kleiner als 1.e-10), wird die Ordnung 5 empfohlen, da sie zu erheblich weniger Designpunkten führt, solange keine Pole oder schweren Enden vorhanden sind.
- u_resolutionfloat, Standardwert:
1e-12 Legt den maximal tolerierbaren u-Fehler fest. Beachten Sie, dass die Auflösung der meisten gleichmäßigen Zufallszahlengeneratoren 2-32 = 2,3e-10 beträgt. Daher führt ein Wert von 1.e-10 zu einem Inversionsalgorithmus, der als exakt bezeichnet werden könnte. Für die meisten Simulationen sind auch etwas größere Werte für den maximalen Fehler ausreichend. Standard ist 1e-12.
- construction_pointsarray_like, optional
Legt Startkonstruktionspunkte (Knoten) für die Hermite-Interpolation fest. Da der mögliche maximale Fehler nur im Setup geschätzt wird, kann es notwendig sein, einige spezielle Designpunkte für die Berechnung der Hermite-Interpolation festzulegen, um sicherzustellen, dass der maximale u-Fehler nicht größer als gewünscht sein kann. Solche Punkte sind Punkte, an denen die Dichte nicht differenzierbar ist oder ein lokales Extremum aufweist.
- random_state{None, int,
numpy.random.Generator, numpy.random.RandomState}, optionalEin NumPy-Zufallszahlengenerator oder Seed für den zugrunde liegenden NumPy-Zufallszahlengenerator, der zum Generieren des Stroms von gleichmäßigen Zufallszahlen verwendet wird. Wenn random_state None ist (oder np.random), wird die
numpy.random.RandomStateSingleton-Instanz verwendet. Wenn random_state ein Integer ist, wird eine neueRandomState-Instanz mit random_state als Seed verwendet. Wenn random_state bereits eineGenerator- oderRandomState-Instanz ist, wird diese Instanz verwendet.
- Attribute:
IntervalleGibt die Anzahl der für die Hermite-Interpolation im Generatorobjekt verwendeten Knoten (Designpunkte) zurück.
- midpoint_error
Methoden
ppf(u)Approximierte PPF (Prozentrangfunktion) der gegebenen Verteilung.
qrvs([size, d, qmc_engine])Quasi-Zufallsvariaten der gegebenen RV.
rvs([size, random_state])Stichprobe aus der Verteilung.
set_random_state([random_state])Setzt den zugrunde liegenden gleichmäßigen Zufallszahlengenerator.
u_error([sample_size])Schätzt den u-Fehler der Approximation mittels Monte-Carlo-Simulation.
Hinweise
NumericalInverseHermiteapproximiert die Umkehrfunktion der CDF einer kontinuierlichen statistischen Verteilung mit einem Hermite-Spline. Die Ordnung des Hermite-Splines kann durch Übergabe des Parameters order festgelegt werden.Wie in [1] beschrieben, beginnt sie mit der Auswertung der PDF und CDF der Verteilung an einem Netz von Quantilen
xinnerhalb des Trägers der Verteilung. Sie verwendet die Ergebnisse, um einen Hermite-SplineHanzupassen, so dassH(p) == x, wobeipdas Array der Perzentile ist, die den Quantilenxentsprechen. Daher approximiert der Spline die Umkehrfunktion der CDF der Verteilung mit Maschinenpräzision an den Perzentilenp, aber typischerweise wird der Spline an den Mittelpunkten zwischen den Perzentilpunkten nicht so genau sein.p_mid = (p[:-1] + p[1:])/2
Daher wird das Netz von Quantilen nach Bedarf verfeinert, um den maximalen „u-Fehler“
u_error = np.max(np.abs(dist.cdf(H(p_mid)) - p_mid))
unter die angegebene Toleranz u_resolution zu reduzieren. Die Verfeinerung stoppt, wenn die erforderliche Toleranz erreicht ist oder wenn die Anzahl der Netzintervalle nach der nächsten Verfeinerung die maximal zulässige Anzahl von Intervallen (100000) überschreiten könnte.
Referenzen
[1]Hörmann, Wolfgang, und Josef Leydold. „Continuous random variate generation by fast numerical inversion.“ ACM Transactions on Modeling and Computer Simulation (TOMACS) 13.4 (2003): 347-362.
[2]UNU.RAN Referenzhandbuch, Abschnitt 5.3.5, „HINV - Hermite interpolation based INVersion of CDF“, https://statmath.wu.ac.at/software/unuran/doc/unuran.html#HINV
Beispiele
>>> from scipy.stats.sampling import NumericalInverseHermite >>> from scipy.stats import norm, genexpon >>> from scipy.special import ndtr >>> import numpy as np
Um einen Generator zur Stichprobenentnahme aus der Standardnormalverteilung zu erstellen, tun Sie Folgendes:
>>> class StandardNormal: ... def pdf(self, x): ... return 1/np.sqrt(2*np.pi) * np.exp(-x**2 / 2) ... def cdf(self, x): ... return ndtr(x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInverseHermite(dist, random_state=urng)
Die
NumericalInverseHermitehat eine Methode, die die PPF der Verteilung approximiert.>>> rng = NumericalInverseHermite(dist) >>> p = np.linspace(0.01, 0.99, 99) # percentiles from 1% to 99% >>> np.allclose(rng.ppf(p), norm.ppf(p)) True
Abhängig von der Implementierung der Zufallsstichprobenmethode der Verteilung können die generierten Zufallsvariaten bei gleichem Zufallsstatus nahezu identisch sein.
>>> dist = genexpon(9, 16, 3) >>> rng = NumericalInverseHermite(dist) >>> # `seed` ensures identical random streams are used by each `rvs` method >>> seed = 500072020 >>> rvs1 = dist.rvs(size=100, random_state=np.random.default_rng(seed)) >>> rvs2 = rng.rvs(size=100, random_state=np.random.default_rng(seed)) >>> np.allclose(rvs1, rvs2) True
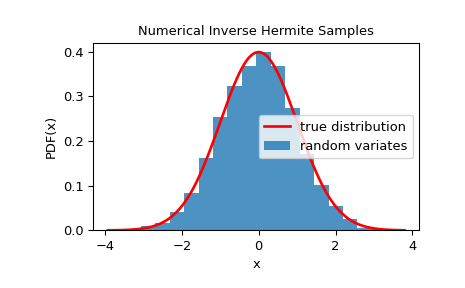
Um zu überprüfen, ob die generierten Zufallsvariaten der gegebenen Verteilung folgen, können wir ihr Histogramm betrachten.
>>> import matplotlib.pyplot as plt >>> dist = StandardNormal() >>> rng = NumericalInverseHermite(dist) >>> rvs = rng.rvs(10000) >>> x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, 1000) >>> fx = norm.pdf(x) >>> plt.plot(x, fx, 'r-', lw=2, label='true distribution') >>> plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates') >>> plt.xlabel('x') >>> plt.ylabel('PDF(x)') >>> plt.title('Numerical Inverse Hermite Samples') >>> plt.legend() >>> plt.show()
Gegeben die Ableitung der PDF nach der Zufallsvariablen (d.h.
x), können wir die PPF mit quintischer Hermite-Interpolation approximieren, indem wir den Parameter order übergeben.>>> class StandardNormal: ... def pdf(self, x): ... return 1/np.sqrt(2*np.pi) * np.exp(-x**2 / 2) ... def dpdf(self, x): ... return -1/np.sqrt(2*np.pi) * x * np.exp(-x**2 / 2) ... def cdf(self, x): ... return ndtr(x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInverseHermite(dist, order=5, random_state=urng)
Höhere Ordnungen ergeben eine geringere Anzahl von Intervallen.
>>> rng3 = NumericalInverseHermite(dist, order=3) >>> rng5 = NumericalInverseHermite(dist, order=5) >>> rng3.intervals, rng5.intervals (3000, 522)
Der u-Fehler kann durch Aufruf der Methode
u_errorgeschätzt werden. Sie führt eine kleine Monte-Carlo-Simulation durch, um den u-Fehler zu schätzen. Standardmäßig werden 100.000 Stichproben verwendet. Dies kann durch Übergabe des Arguments sample_size geändert werden.>>> rng1 = NumericalInverseHermite(dist, u_resolution=1e-10) >>> rng1.u_error(sample_size=1000000) # uses one million samples UError(max_error=9.53167544892608e-11, mean_absolute_error=2.2450136432146864e-11)
Dies gibt ein benanntes Tupel zurück, das den maximalen u-Fehler und den mittleren absoluten u-Fehler enthält.
Der u-Fehler kann durch Verringern der u-Auflösung (maximal zulässiger u-Fehler) reduziert werden.
>>> rng2 = NumericalInverseHermite(dist, u_resolution=1e-13) >>> rng2.u_error(sample_size=1000000) UError(max_error=9.32027892364129e-14, mean_absolute_error=1.5194172675685075e-14)
Beachten Sie, dass dies mit erhöhter Einrichtungszeit und einer größeren Anzahl von Intervallen verbunden ist.
>>> rng1.intervals 1022 >>> rng2.intervals 5687 >>> from timeit import timeit >>> f = lambda: NumericalInverseHermite(dist, u_resolution=1e-10) >>> timeit(f, number=1) 0.017409582000254886 # may vary >>> f = lambda: NumericalInverseHermite(dist, u_resolution=1e-13) >>> timeit(f, number=1) 0.08671202100003939 # may vary
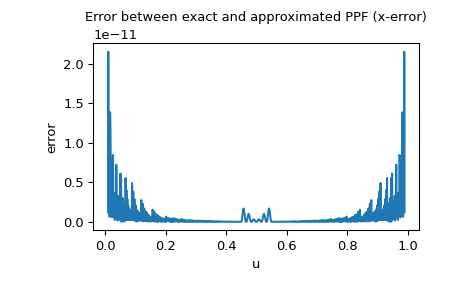
Da die PPF der Normalverteilung als Spezialfunktion verfügbar ist, können wir auch den x-Fehler überprüfen, d.h. die Differenz zwischen der approximierten PPF und der exakten PPF.
>>> import matplotlib.pyplot as plt >>> u = np.linspace(0.01, 0.99, 1000) >>> approxppf = rng.ppf(u) >>> exactppf = norm.ppf(u) >>> error = np.abs(exactppf - approxppf) >>> plt.plot(u, error) >>> plt.xlabel('u') >>> plt.ylabel('error') >>> plt.title('Error between exact and approximated PPF (x-error)') >>> plt.show()