Normaltest#
Die Funktion scipy.stats.normaltest testet die Nullhypothese, dass eine Stichprobe aus einer Normalverteilung stammt. Sie basiert auf dem D’Agostino und Pearson [1] [2] Test, der Schiefe und Kurtosis kombiniert, um einen Omnibustest auf Normalität zu erstellen.
Angenommen, wir möchten anhand von Messungen schlussfolgern, ob die Gewichte erwachsener Männer in einer medizinischen Studie nicht normalverteilt sind [3]. Die Gewichte (lbs) sind im folgenden Array x aufgeführt.
import numpy as np
x = np.array([148, 154, 158, 160, 161, 162, 166, 170, 182, 195, 236])
Der Normalitätstest scipy.stats.normaltest von [1] und [2] beginnt mit der Berechnung einer Statistik, die auf der Stichprobenschiefe und Kurtosis basiert.
from scipy import stats
res = stats.normaltest(x)
res.statistic
np.float64(13.034263121192582)
(Der Test warnt, dass unsere Stichprobe zu wenige Beobachtungen hat, um den Test durchzuführen. Wir werden am Ende des Beispiels darauf zurückkommen.) Da die Normalverteilung eine Schiefe von Null und eine Kurtosis von Null („Überschuss“ oder „Fisher“) hat, tendiert der Wert dieser Statistik für aus einer Normalverteilung gezogene Stichproben zu niedrigen Werten.
Der Test wird durchgeführt, indem der beobachtete Wert der Statistik mit der Nullverteilung verglichen wird: der Verteilung der Statistikwerte, die unter der Nullhypothese abgeleitet wurden, dass die Gewichte aus einer Normalverteilung stammen. Für diesen Normalitätstest ist die Nullverteilung für sehr große Stichproben die Chi-Quadrat-Verteilung mit zwei Freiheitsgraden.
import matplotlib.pyplot as plt
dist = stats.chi2(df=2)
stat_vals = np.linspace(0, 16, 100)
pdf = dist.pdf(stat_vals)
fig, ax = plt.subplots(figsize=(8, 5))
def plot(ax): # we'll reuse this
ax.plot(stat_vals, pdf)
ax.set_title("Normality Test Null Distribution")
ax.set_xlabel("statistic")
ax.set_ylabel("probability density")
plot(ax)
plt.show()
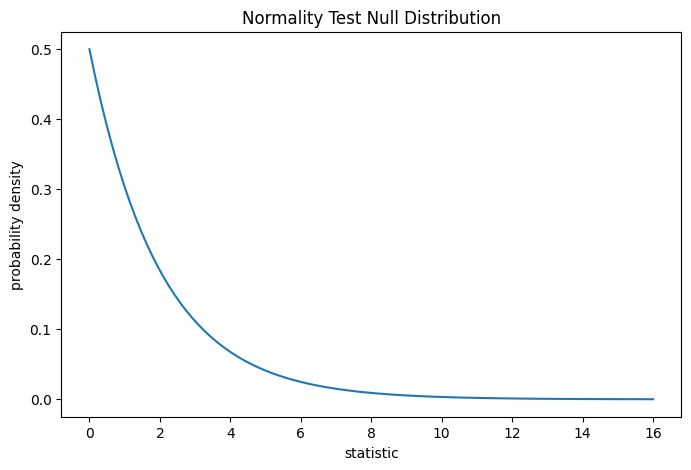
Der Vergleich wird durch den p-Wert quantifiziert: der Anteil der Werte in der Nullverteilung, die größer oder gleich dem beobachteten Wert der Statistik sind.
fig, ax = plt.subplots(figsize=(8, 5))
plot(ax)
pvalue = dist.sf(res.statistic)
annotation = (f'p-value={pvalue:.6f}\n(shaded area)')
props = dict(facecolor='black', width=1, headwidth=5, headlength=8)
_ = ax.annotate(annotation, (13.5, 5e-4), (14, 5e-3), arrowprops=props)
i = stat_vals >= res.statistic # index more extreme statistic values
ax.fill_between(stat_vals[i], y1=0, y2=pdf[i])
ax.set_xlim(8, 16)
ax.set_ylim(0, 0.01)
plt.show()
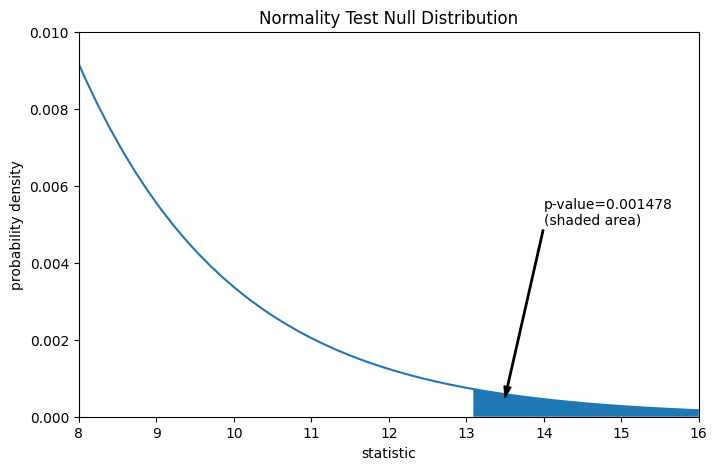
res.pvalue
np.float64(0.0014779023013100172)
Wenn der p-Wert "klein" ist - d.h. wenn die Wahrscheinlichkeit gering ist, aus einer normalverteilten Population Daten zu ziehen, die einen derart extremen Wert der Statistik erzeugen -, kann dies als Hinweis gegen die Nullhypothese zugunsten der Alternativhypothese gewertet werden: die Gewichte wurden nicht aus einer Normalverteilung gezogen. Beachten Sie, dass
Das Umgekehrte gilt nicht; d.h. der Test wird nicht verwendet, um Beweise für die Nullhypothese zu liefern.
Die Schwelle für Werte, die als „klein“ angesehen werden, ist eine Wahl, die vor der Analyse der Daten getroffen werden sollte [4], unter Berücksichtigung der Risiken sowohl von falsch positiven Ergebnissen (fälschlicherweise Ablehnen der Nullhypothese) als auch von falsch negativen Ergebnissen (Nicht-Ablehnen einer falschen Nullhypothese).
Beachten Sie, dass die Chi-Quadrat-Verteilung eine asymptotische Annäherung der Nullverteilung darstellt; sie ist nur für Stichproben mit vielen Beobachtungen genau. Dies ist der Grund, warum wir zu Beginn des Beispiels eine Warnung erhalten haben; unsere Stichprobe ist ziemlich klein. In diesem Fall kann scipy.stats.monte_carlo_test eine genauere, wenn auch stochastische, Annäherung des exakten p-Werts liefern.
def statistic(x, axis):
# Get only the `normaltest` statistic; ignore approximate p-value
return stats.normaltest(x, axis=axis).statistic
res = stats.monte_carlo_test(x, stats.norm.rvs, statistic,
alternative='greater')
fig, ax = plt.subplots(figsize=(8, 5))
plot(ax)
ax.hist(res.null_distribution, np.linspace(0, 25, 50),
density=True)
ax.legend(['asymptotic approximation (many observations)',
'Monte Carlo approximation (11 observations)'])
ax.set_xlim(0, 14)
plt.show()
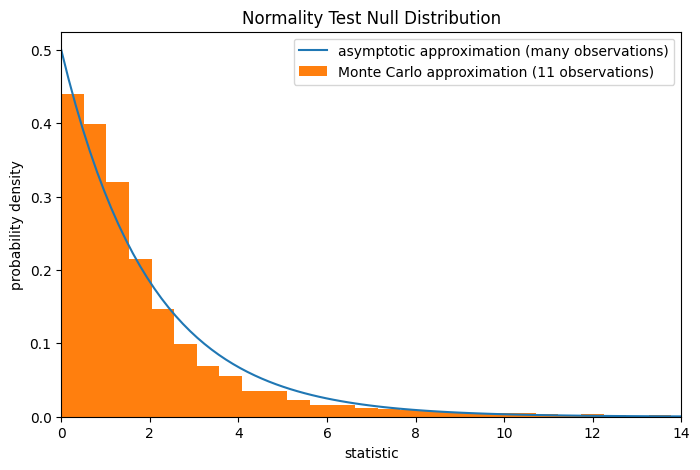
res.pvalue
np.float64(0.0075)
Darüber hinaus können p-Werte, die auf diese Weise berechnet werden, trotz ihrer stochastischen Natur verwendet werden, um die Rate der falschen Ablehnungen der Nullhypothese genau zu kontrollieren [5].