Shapiro-Wilk-Test für Normalverteilung#
Nehmen wir an, wir möchten anhand von Messungen schlussfolgern, ob die Gewichte erwachsener menschlicher Männer in einer medizinischen Studie nicht normalverteilt sind [1]. Die Gewichte (in lbs) sind im unten stehenden Array x aufgeführt.
import numpy as np
x = np.array([148, 154, 158, 160, 161, 162, 166, 170, 182, 195, 236])
Der Normalitätstest scipy.stats.shapiro von [1] und [2] beginnt mit der Berechnung einer Statistik, die auf der Beziehung zwischen den Beobachtungen und den erwarteten Ordnungsstatistiken einer Normalverteilung basiert.
from scipy import stats
res = stats.shapiro(x)
res.statistic
np.float64(0.7888146948631716)
Der Wert dieser Statistik ist tendenziell hoch (nahe 1) für Stichproben, die aus einer Normalverteilung gezogen wurden.
Der Test wird durchgeführt, indem der beobachtete Wert der Statistik mit der Nullverteilung verglichen wird: der Verteilung der Statistikwerte, die unter der Nullhypothese gebildet werden, dass die Gewichte aus einer Normalverteilung stammen. Für diesen Normalitätstest ist die Nullverteilung nicht einfach exakt zu berechnen, daher wird sie normalerweise durch Monte-Carlo-Methoden angenähert, d. h. es werden viele Stichproben derselben Größe wie x aus einer Normalverteilung gezogen und für jede davon die Werte der Statistik berechnet.
def statistic(x):
# Get only the `shapiro` statistic; ignore its p-value
return stats.shapiro(x).statistic
ref = stats.monte_carlo_test(x, stats.norm.rvs, statistic,
alternative='less')
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8, 5))
bins = np.linspace(0.65, 1, 50)
def plot(ax): # we'll reuse this
ax.hist(ref.null_distribution, density=True, bins=bins)
ax.set_title("Shapiro-Wilk Test Null Distribution \n"
"(Monte Carlo Approximation, 11 Observations)")
ax.set_xlabel("statistic")
ax.set_ylabel("probability density")
plot(ax)
plt.show()
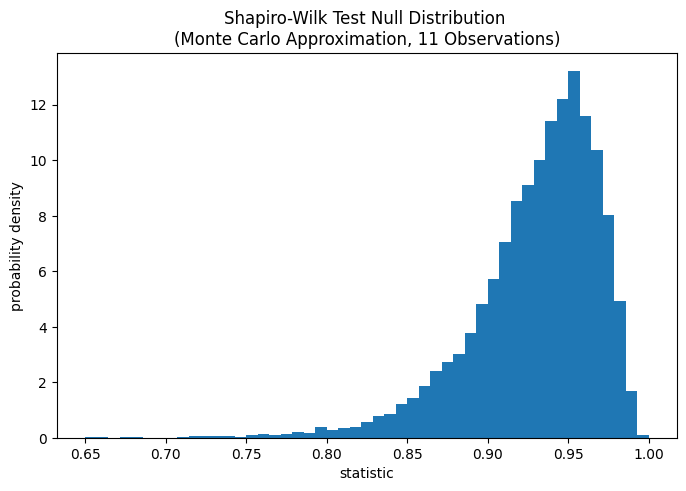
Der Vergleich wird durch den p-Wert quantifiziert: dem Anteil der Werte in der Nullverteilung, die kleiner oder gleich dem beobachteten Wert der Statistik sind.
fig, ax = plt.subplots(figsize=(8, 5))
plot(ax)
annotation = (f'p-value={res.pvalue:.6f}\n(highlighted area)')
props = dict(facecolor='black', width=1, headwidth=5, headlength=8)
_ = ax.annotate(annotation, (0.75, 0.1), (0.68, 0.7), arrowprops=props)
i_extreme = np.where(bins <= res.statistic)[0]
for i in i_extreme:
ax.patches[i].set_color('C1')
plt.xlim(0.65, 0.9)
plt.ylim(0, 4)
plt.show()
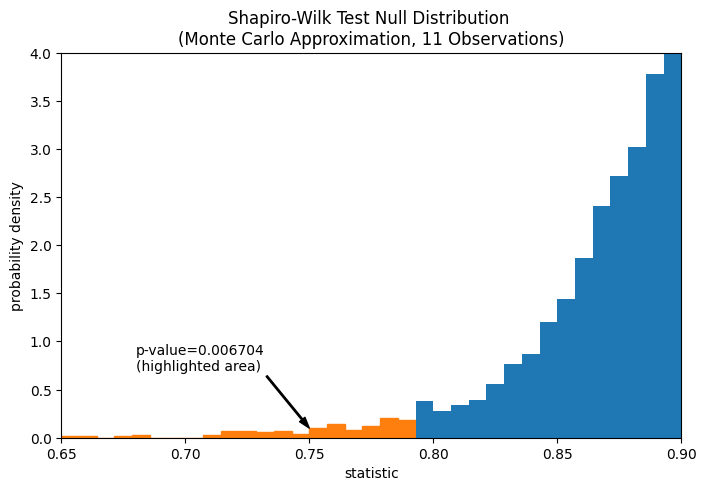
res.pvalue
np.float64(0.006703814061898823)
Wenn der p-Wert "klein" ist - d.h. wenn die Wahrscheinlichkeit gering ist, aus einer normalverteilten Population Daten zu ziehen, die einen derart extremen Wert der Statistik erzeugen -, kann dies als Hinweis gegen die Nullhypothese zugunsten der Alternativhypothese gewertet werden: die Gewichte wurden nicht aus einer Normalverteilung gezogen. Beachten Sie, dass
Umgekehrt ist es nicht wahr; das heißt, der Test wird nicht verwendet, um Beweise *für* die Nullhypothese zu liefern.
Die Schwelle für Werte, die als „klein“ betrachtet werden, ist eine Wahl, die getroffen werden sollte, bevor die Daten analysiert werden [3], unter Berücksichtigung der Risiken sowohl von falsch positiven Ergebnissen (fälschlicherweise Ablehnung der Nullhypothese) als auch von falsch negativen Ergebnissen (Nichtablehnung einer falschen Nullhypothese).