Universelles Nicht-Uniformes Zufallszahlensampeln in SciPy#
SciPy bietet eine Schnittstelle zu vielen universellen nicht-uniformen Zufallszahlengeneratoren, um Zufallsvariaten aus einer breiten Palette von univariaten kontinuierlichen und diskreten Verteilungen zu sampeln. Implementierungen einer schnellen C-Bibliothek namens UNU.RAN werden für Geschwindigkeit und Leistung verwendet. Bitte konsultieren Sie die Dokumentation von UNU.RAN für eine eingehende Erklärung dieser Methoden. Sie wird für die Erstellung dieses Tutorials und die Dokumentation aller Generatoren intensiv herangezogen.
Einleitung#
Die Erzeugung von Zufallsvariaten ist ein kleines Forschungsgebiet, das sich mit Algorithmen zur Erzeugung von Zufallsvariaten aus verschiedenen Verteilungen befasst. Üblicherweise wird angenommen, dass ein uniformer Zufallszahlengenerator verfügbar ist. Dies ist ein Programm, das eine Sequenz von unabhängigen und identisch verteilten kontinuierlichen U(0,1)-Zufallsvariaten (d. h. uniforme Zufallsvariaten im Intervall (0,1)) erzeugt. Natürlich können reale Computer niemals ideale Zufallszahlen erzeugen und auch keine Zahlen beliebiger Präzision produzieren, aber hochmoderne uniforme Zufallszahlengeneratoren kommen diesem Ziel nahe. Daher befasst sich die Erzeugung von Zufallsvariaten mit dem Problem, eine solche Sequenz von U(0,1)-Zufallszahlen in nicht-uniforme Zufallsvariaten umzuwandeln. Diese Methoden sind universell und funktionieren im Black-Box-Verfahren.
Einige Methoden hierfür sind:
Die Inversionsmethode: Wenn die Umkehrfunktion \(F^{-1}\) der kumulativen Verteilungsfunktion bekannt ist, ist die Erzeugung von Zufallsvariaten einfach. Wir erzeugen einfach eine uniform verteilte U(0,1)-Zufallszahl U und geben \(X = F^{-1}(U)\) zurück. Da geschlossene Formen für die Umkehrfunktion selten verfügbar sind, muss man sich in der Regel auf Näherungen der Umkehrfunktion verlassen (z. B.
scipy.special.ndtri,scipy.special.stdtrit). Im Allgemeinen ist die Implementierung spezieller Funktionen im Vergleich zu den Inversionsmethoden in UNU.RAN recht langsam.Die Ablehnmethode: Die Ablehnmethode, oft als Akzeptanz-Ablehn-Methode bezeichnet, wurde 1951 von John von Neumann vorgeschlagen[1]. Sie beinhaltet die Berechnung einer Obergrenze für die Dichtefunktion (auch Hut-Funktion genannt) und die Verwendung der Inversionsmethode zur Erzeugung einer Zufallsvariable, sagen wir Y, aus dieser Obergrenze. Dann kann eine uniforme Zufallszahl zwischen 0 und dem Wert der Obergrenze bei Y gezogen werden. Wenn diese Zahl kleiner als der Wert der Dichtefunktion bei Y ist, wird die Stichprobe zurückgegeben, andernfalls wird sie abgelehnt. Siehe
scipy.stats.sampling.TransformedDensityRejection.Die Quotient-aus-Uniformen-Methode: Dies ist eine Art von Akzeptanz-Ablehn-Methode, die minimale umschließende Rechtecke verwendet, um die Hut-Funktion zu konstruieren. Siehe
scipy.stats.sampling.RatioUniforms.Inversion für diskrete Verteilungen: Der Unterschied zum kontinuierlichen Fall ist, dass \(F\) nun eine Stufenfunktion ist. Um dies auf einem Computer zu realisieren, wird ein Suchalgorithmus verwendet, der einfachste davon ist die *sequentielle Suche*. Eine uniforme Zufallszahl wird aus U(0, 1) erzeugt und Wahrscheinlichkeiten werden summiert, bis die kumulative Wahrscheinlichkeit die uniforme Zufallszahl überschreitet. Der Index, an dem dies geschieht, ist die gesuchte Zufallsvariable und wird zurückgegeben.
Weitere Details zu diesen Algorithmen finden Sie im Anhang des UNU.RAN-Benutzerhandbuchs.
Bei der Erzeugung von Zufallsvariaten aus einer Verteilung sind zwei Faktoren wichtig, um die Geschwindigkeit eines Generators zu bestimmen: der Einrichtigungsschritt und das eigentliche Sampling. Je nach Situation können unterschiedliche Generatoren optimal sein. Wenn man beispielsweise wiederholt große Stichproben aus einer bestimmten Verteilung mit einem festen Formparameter ziehen muss, ist eine langsame Einrichtung akzeptabel, wenn das Sampling schnell erfolgt. Dies nennt man den Fall des festen Parameters. Wenn man Stichproben aus einer Verteilung für verschiedene Formparameter ziehen möchte (Fall des variablen Parameters), würde eine aufwendige Einrichtung, die für jeden Parameter wiederholt werden muss, zu einer sehr schlechten Leistung führen. In einer solchen Situation ist eine schnelle Einrichtung entscheidend, um eine gute Leistung zu erzielen. Eine Übersicht über die Einrichtungs- und Samplinggeschwindigkeit der verschiedenen Methoden zeigt die folgende Tabelle.
Methoden für kontinuierliche Verteilungen |
Erforderliche Eingaben |
Optionale Eingaben |
Einrichtungsgeschwindigkeit |
Samplinggeschwindigkeit |
|---|---|---|---|---|
pdf, dpdf |
keine |
langsam |
schnell |
|
cdf |
pdf, dpdf |
(sehr) langsam |
(sehr) schnell |
|
cdf |
(sehr) langsam |
(sehr) schnell |
||
keine |
schnell |
langsam |
wo
pdf: Wahrscheinlichkeitsdichtefunktion
dpdf: Ableitung der pdf
cdf: kumulative Verteilungsfunktion
Um die numerische Inversionsmethode NumericalInversePolynomial mit minimalem Aufwand auf eine große Anzahl kontinuierlicher Verteilungen in SciPy anzuwenden, werfen Sie einen Blick auf scipy.stats.sampling.FastGeneratorInversion.
Methoden für diskrete Verteilungen |
Erforderliche Eingaben |
Optionale Eingaben |
Einrichtungsgeschwindigkeit |
Samplinggeschwindigkeit |
|---|---|---|---|---|
pv |
pmf |
langsam |
sehr schnell |
|
pv |
pmf |
langsam |
sehr schnell |
wo
pv: Wahrscheinlichkeitsvektor
pmf: Wahrscheinlichkeitsmassenfunktion
Weitere Details zu den in UNU.RAN implementierten Generatoren finden Sie unter [2] und [3].
Grundlegende Konzepte der Schnittstelle#
Jeder Generator muss eingerichtet werden, bevor man damit sampeln kann. Dies geschieht durch Instanziierung eines Objekts dieser Klasse. Die meisten Generatoren nehmen ein Verteilungsobjekt als Eingabe, das die Implementierung der erforderlichen Methoden wie PDF, CDF usw. enthält. Zusätzlich zum Verteilungsobjekt können auch Parameter zur Einrichtung des Generators übergeben werden. Es ist auch möglich, die Verteilungen mit einem domain-Parameter zu kürzen. Alle Generatoren benötigen einen Strom von uniformen Zufallszahlen, der in Zufallsvariaten der gegebenen Verteilung umgewandelt wird. Dies geschieht durch Übergabe eines random_state-Parameters mit einem NumPy BitGenerator als uniformen Zufallszahlengenerator. random_state kann entweder ein Integer, ein numpy.random.Generator oder ein numpy.random.RandomState sein.
Warnung
Die Verwendung von NumPy < 1.19.0 wird nicht empfohlen, da es keine schnelle Cython-API zum Generieren von uniformen Zufallszahlen hat und für den praktischen Gebrauch zu langsam sein könnte.
Alle Generatoren verfügen über eine gemeinsame rvs-Methode, mit der Stichproben aus der gegebenen Verteilung gezogen werden können.
Ein Beispiel für diese Schnittstelle wird unten gezeigt
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
import numpy as np
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
Wie im Beispiel gezeigt, initialisieren wir zunächst ein Verteilungsobjekt, das eine Implementierung der vom Generator benötigten Methoden enthält. In unserem Fall verwenden wir die Methode TransformedDensityRejection (TDR), die eine PDF und ihre Ableitung nach x (d. h. der Variate) benötigt.
Hinweis
Beachten Sie, dass die Methoden des Verteilungsobjekts (d. h. pdf, dpdf usw.) nicht vektorisiert sein müssen. Sie sollten Floats akzeptieren und zurückgeben.
Hinweis
Man kann auch SciPy-Verteilungen als Argumente übergeben. Beachten Sie jedoch, dass das Objekt nicht immer alle Informationen enthält, die für einige Generatoren erforderlich sind, wie z. B. die Ableitung der PDF für die TDR-Methode. Die Verwendung von SciPy-Verteilungen kann die Leistung auch aufgrund der Vektorisierung von Methoden wie pdf und cdf reduzieren. In beiden Fällen kann man ein benutzerdefiniertes Verteilungsobjekt implementieren, das alle erforderlichen Methoden enthält und nicht vektorisiert ist, wie im obigen Beispiel gezeigt. Wenn man eine numerische Inversionsmethode auf eine in SciPy definierte Verteilung anwenden möchte, werfen Sie bitte auch einen Blick auf scipy.stats.sampling.FastGeneratorInversion.
Im obigen Beispiel haben wir ein Objekt der Methode TransformedDensityRejection eingerichtet, um aus einer Standard-Normalverteilung zu sampeln. Nun können wir mit dem Sampling aus unserer Verteilung beginnen, indem wir die rvs-Methode aufrufen.
rng.rvs()
0.02993054902042954
rng.rvs((5, 3))
array([[ 0.53298415, 1.43877957, 3.59914818],
[-0.84078139, -0.69554656, -0.52440591],
[ 0.01225487, -0.00454614, -0.28462863],
[ 0.82790149, -0.72765527, 1.20739908],
[-1.56792816, -1.15971132, -0.56065036]])
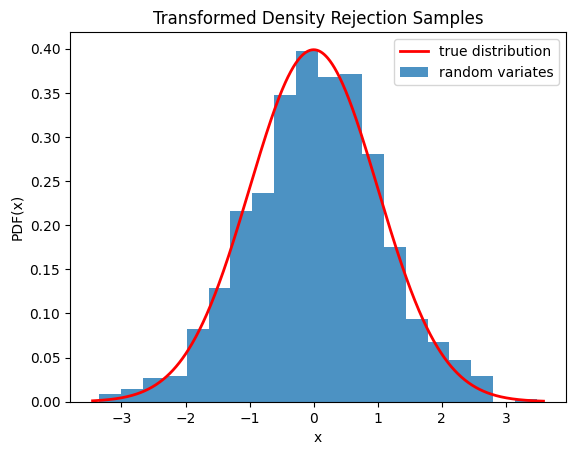
Wir können auch überprüfen, ob die Stichproben aus der richtigen Verteilung stammen, indem wir das Histogramm der Stichproben visualisieren.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
rvs = rng.rvs(size=1000)
x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, num=1000)
fx = norm.pdf(x)
plt.plot(x, fx, 'r-', lw=2, label='true distribution')
plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates')
plt.xlabel('x')
plt.ylabel('PDF(x)')
plt.title('Transformed Density Rejection Samples')
plt.legend()
plt.show()
Hinweis
Bitte beachten Sie den Unterschied zwischen der rvs-Methode der Verteilungen in scipy.stats und der, die von diesen Generatoren bereitgestellt wird. UNU.RAN-Generatoren müssen als unabhängig betrachtet werden, in dem Sinne, dass sie im Allgemeinen einen anderen Strom von Zufallszahlen erzeugen als die äquivalente Verteilung in scipy.stats für jeden Seed. Die Implementierung von rvs in scipy.stats.rv_continuous stützt sich in der Regel auf das NumPy-Modul numpy.random für bekannte Verteilungen (z. B. für die Normalverteilung, die Beta-Verteilung) und Transformationen anderer Verteilungen (z. B. Normal-Inverse-Gauss scipy.stats.norminvgauss und die Lognormalverteilung scipy.stats.lognorm). Wenn keine spezielle Methode implementiert ist, greift scipy.stats.rv_continuous standardmäßig auf eine numerische Inversionsmethode der CDF zurück, die sehr langsam ist. Da UNU.RAN uniforme Zufallszahlen anders als SciPy oder NumPy transformiert, ist der resultierende Strom von RVs unterschiedlich, selbst für denselben Strom von uniformen Zufallszahlen. Zum Beispiel wären die Zufallszahlströme von SciPy's scipy.stats.norm und UNU.RAN's TransformedDensityRejection nicht gleich, selbst bei demselben random_state.
from scipy.stats.sampling import norm, TransformedDensityRejection
from copy import copy
dist = StandardNormal()
urng1 = np.random.default_rng()
urng1_copy = copy(urng1)
rng = TransformedDensityRejection(dist, random_state=urng1)
rng.rvs()
# -1.526829048388144
norm.rvs(random_state=urng1_copy)
# 1.3194816698862635
Wir können einen domain-Parameter übergeben, um die Verteilung zu kürzen.
rng = TransformedDensityRejection(dist, domain=(-1, 1), random_state=urng)
rng.rvs((5, 3))
array([[-3.87146100e-01, -3.07151677e-01, 4.47624310e-01],
[ 4.48644826e-01, 3.20296629e-01, -2.60817423e-01],
[ 6.44967243e-01, 3.23975875e-01, 1.55647870e-01],
[-7.92407003e-04, -7.72789588e-01, -5.12837415e-01],
[-7.30184717e-01, 9.35027888e-01, 2.63935531e-01]])
Ungültige und fehlerhafte Argumente werden entweder von SciPy oder von UNU.RAN behandelt. Letzteres wirft einen UNURANError, der einem gemeinsamen Format folgt.
UNURANError: [objid: <object id>] <error code>: <reason> => <type of error>
wo
<object id>ist die ID des von UNU.RAN vergebenen Objekts.<error code>ist ein Fehlercode, der einen Fehlertyp darstellt.<reason>ist der Grund, warum der Fehler aufgetreten ist.<type of error>ist eine kurze Beschreibung des Fehlertyps.
Der <reason> zeigt, was den Fehler verursacht hat. Dieser allein sollte genügend Informationen enthalten, um bei der Fehlersuche zu helfen. Zusätzlich können <error id> und <type of error> verwendet werden, um verschiedene Fehlerklassen in UNU.RAN zu untersuchen. Eine vollständige Liste aller Fehlercodes und ihrer Beschreibungen finden Sie in Abschnitt 8.4 des UNU.RAN-Benutzerhandbuchs.
Ein Beispiel für einen von UNU.RAN generierten Fehler wird unten gezeigt.
UNURANError: [objid: TDR.003] 50 : PDF(x) < 0.! => (generator) (possible) invalid data
Dies zeigt, dass UNU.RAN ein Objekt mit der ID TDR.003 nicht initialisieren konnte, weil die PDF < 0 war, d. h. negativ. Dies fällt unter den Typ „mögliche ungültige Daten für den Generator“ und hat den Fehlercode 50.
Warnungen, die von UNU.RAN ausgegeben werden, folgen ebenfalls diesem Format.